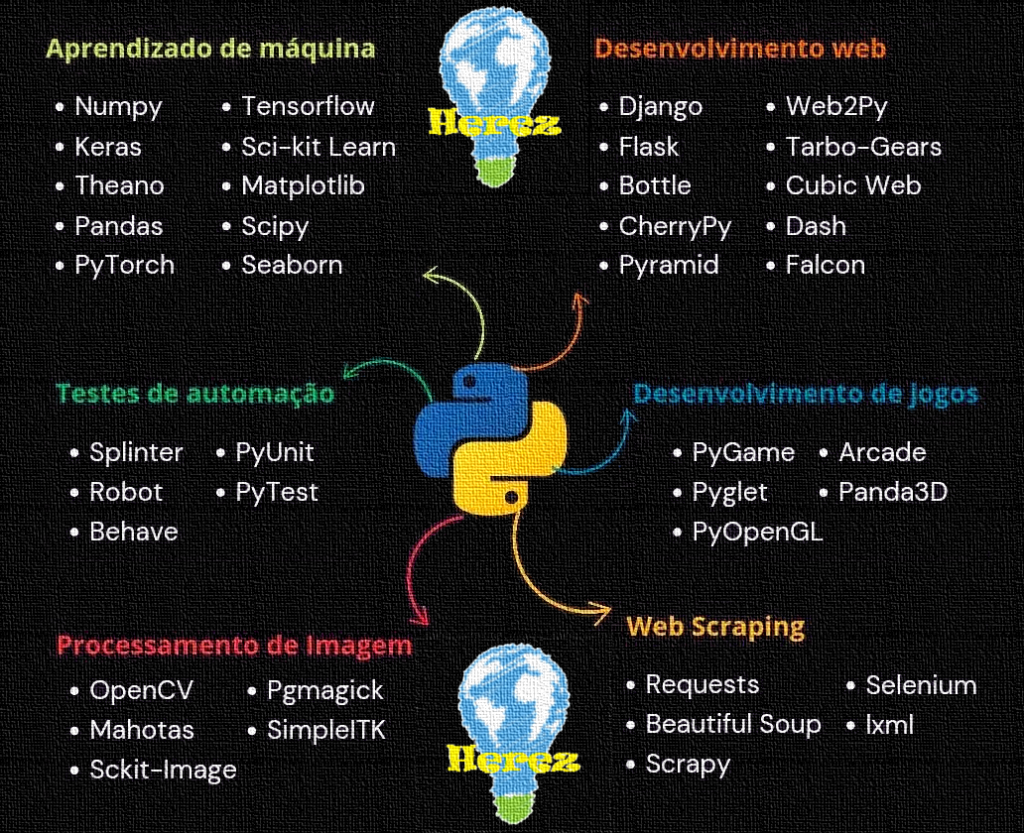
Bibliotecas Python para Aprendizado de Máquina — Parte 1 da série de posts do Guia Herez
Visão geral: existem muitas bibliotecas Python úteis para diferentes etapas do fluxo de trabalho de Machine Learning. Por isso esta publicação faz parte de uma série que agrupa bibliotecas por área: Aprendizado de Máquina, Desenvolvimento Web, Testes Automatizados, Processamento de Imagens, Web Scraping e Desenvolvimento de Jogos. Este é o primeiro post da série e foca nas bibliotecas essenciais para aprendizado de máquina.
Publicado por Herez em
Como usar este post
Este artigo apresenta cada biblioteca com uma breve descrição, motivos para usar, comandos de instalação e exemplos de casos de uso. Use-o como referência rápida ao montar ambientes, escolher ferramentas para prototipagem ou planejar pipelines de ML.
Resumo rápido
| Biblioteca | Função principal | Quando usar |
|---|---|---|
| NumPy | Arrays N‑dimensionais e operações numéricas | Base para cálculos e outras bibliotecas |
| Pandas | Manipulação de dados tabulares | ETL, análise exploratória, feature engineering |
| Matplotlib | Plotagem 2D | Gráficos personalizados e publicação |
| Seaborn | Visualização estatística de alto nível | Exploração de dados e relatórios |
| SciPy | Rotinas científicas avançadas | Otimização, integração, álgebra avançada |
| scikit-learn | Algoritmos clássicos de ML | Modelos de baseline e pipelines |
| TensorFlow | Framework de deep learning escalável | Produção, treinamento em larga escala |
| Keras | API de alto nível para redes neurais | Prototipagem rápida de modelos |
| PyTorch | Framework de deep learning com execução dinâmica | Pesquisa e modelos customizados |
| Theano | Compilador de expressões matemáticas (histórico) | Legado e compreensão histórica |
Bibliotecas detalhadas
NumPy
O que é: biblioteca fundamental para computação numérica em Python. Fornece o tipo ndarray e operações vetorizadas de alto desempenho.
Por que usar: base para Pandas, SciPy e muitos frameworks de ML; substitui loops Python por operações vetorizadas, acelerando cálculos.
# Instalação
pip install numpy
Casos de uso: álgebra linear, manipulação de tensores simples, geração de dados sintéticos e operações matriciais em pipelines de pré‑processamento.
Pandas
O que é: biblioteca para manipulação e análise de dados tabulares com estruturas DataFrame e Series.
# Instalação
pip install pandas
Casos de uso: ETL, análise exploratória (EDA), tratamento de valores ausentes, criação de features e integração com scikit‑learn.
Matplotlib
O que é: biblioteca clássica de plotagem 2D; altamente configurável e a base para muitas outras bibliotecas de visualização.
# Instalação
pip install matplotlib
Seaborn
O que é: camada de alto nível sobre Matplotlib para visualizações estatísticas com estética pronta.
# Instalação
pip install seaborn
SciPy
O que é: conjunto de algoritmos científicos construído sobre NumPy, incluindo otimização, integração, interpolação, álgebra linear avançada e estatística.
# Instalação
pip install scipy
scikit-learn
O que é: biblioteca padrão para algoritmos clássicos de machine learning: regressão, classificação, clustering, redução de dimensionalidade e pipelines.
# Instalação
pip install scikit-learn
TensorFlow
O que é: framework de deep learning escalável, com suporte a CPU, GPU e TPU, e um ecossistema para produção.
# Instalação
pip install tensorflow
Keras
O que é: API de alto nível para construção e treino de redes neurais; atualmente integrada ao TensorFlow como tf.keras.
# Instalação (opcional se usar tf.keras)
pip install keras
PyTorch
O que é: framework de deep learning com execução dinâmica (eager execution), muito usado em pesquisa e com forte comunidade.
# Instalação
pip install torch torchvision
Theano
O que é: biblioteca histórica para definição e otimização de expressões matemáticas que geram código eficiente para CPU/GPU.
# Instalação
pip install Theano
Como escolher a combinação certa
- Preparação de dados: NumPy + Pandas + SciPy.
- Visualização: Matplotlib para controle fino; Seaborn para análises estatísticas rápidas.
- Modelos clássicos: scikit‑learn para protótipos e pipelines.
- Deep learning: TensorFlow/Keras para produção; PyTorch para pesquisa e experimentação.
Boas práticas
- Use ambientes virtuais (
venv,conda) para isolar dependências. - Documente versões das bibliotecas (arquivo
requirements.txtouenvironment.yml) para reprodutibilidade. - Ao usar GPU, verifique compatibilidade entre versões de CUDA/cuDNN e as bibliotecas (TensorFlow/PyTorch).
- Combine bibliotecas: Pandas para ETL, scikit‑learn para baseline, e TensorFlow/PyTorch para modelos complexos.
Próximo post da série
No próximo artigo cobriremos bibliotecas Python para Testes Automatizados (Splinter, Robot, Behave, PyUnit e PyTest), com comparações práticas e cenários de uso. Veja o próximo post.