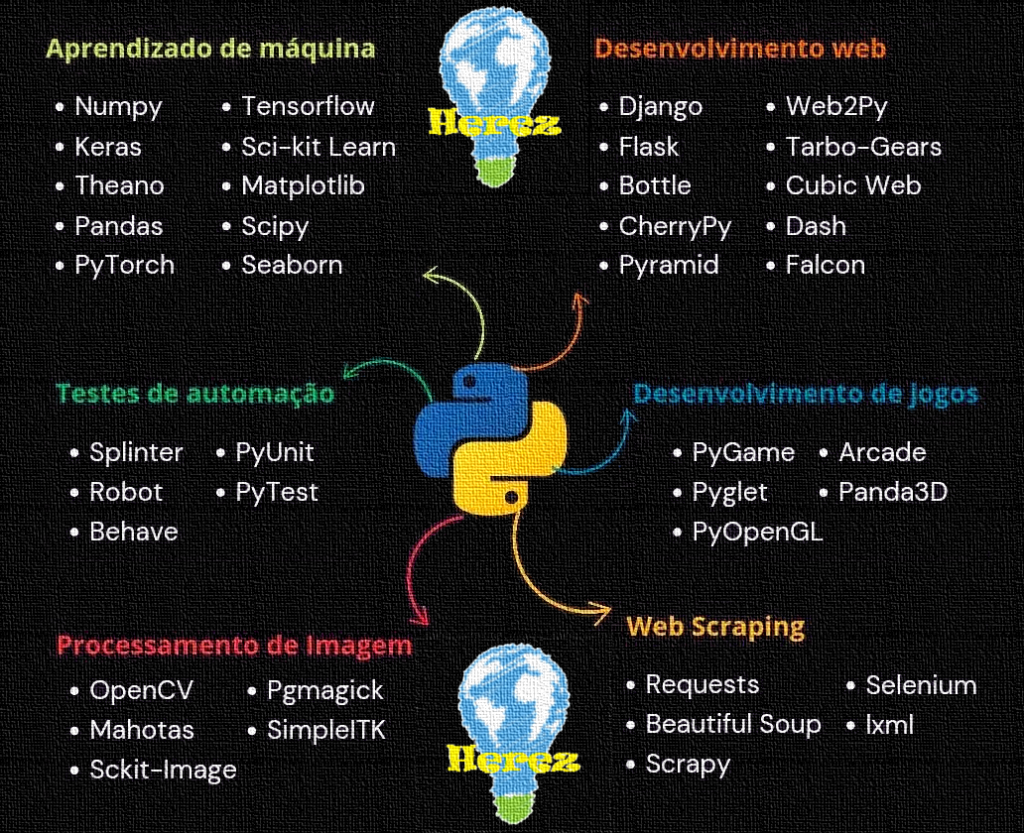
Web Scraping com Python — Parte 6 da série Herez
Visão geral: esta é a sexta publicação da série Herez sobre bibliotecas Python. Aqui detalhamos as ferramentas essenciais para Web Scraping: Requests, BeautifulSoup, Scrapy, Selenium e lxml. Cada seção traz descrição, instalação, exemplos simples e completos de scraping usados em projetos reais por Herez. Exemplos e pipelines completos estão disponíveis nos repositórios GitHub e GitLab da Herez.
Publicado por Herez em
Como usar este post
Este guia apresenta cada biblioteca com exemplos práticos, incluindo scripts completos e reproduzíveis que Herez usou em projetos reais. Use os trechos para aprender a coletar dados de páginas estáticas e dinâmicas, montar crawlers e processar HTML/XML com XPath.
Resumo rápido
| Biblioteca | Função principal | Quando usar |
|---|---|---|
| Requests | Requisições HTTP simples | Páginas estáticas e APIs |
| BeautifulSoup | Parsing HTML fácil | Extração de dados de HTML |
| Scrapy | Crawling e scraping em escala | Projetos de coleta em larga escala |
| Selenium | Automação de navegador | Páginas com JavaScript dinâmico |
| lxml | Parsing rápido com XPath | Extração robusta e performance |
Bibliotecas detalhadas com exemplos completos
Requests
O que é: biblioteca simples e elegante para fazer requisições HTTP em Python.
# Instalação
pip install requests
import requests
url = 'https://example.com'
resp = requests.get(url, timeout=10)
if resp.status_code == 200:
with open('example.html', 'w', encoding='utf-8') as f:
f.write(resp.text)
print('Página salva em example.html')
else:
print('Erro', resp.status_code)Contexto Herez: usado como etapa inicial em pipelines para baixar páginas antes de parse; scripts de download em lote estão nos repositórios Herez.
BeautifulSoup
O que é: parser de HTML que facilita navegar e extrair elementos do DOM com uma API intuitiva.
# Instalação
pip install beautifulsoup4
# opcionalmente instalar lxml para performance
pip install lxml
import requests
from bs4 import BeautifulSoup
url = 'https://example.com/news'
resp = requests.get(url, timeout=10)
soup = BeautifulSoup(resp.text, 'lxml')
articles = []
for item in soup.select('article h2 a'):
title = item.get_text(strip=True)
link = item['href']
articles.append({'title': title, 'link': link})
print(articles)Contexto Herez: usado em projetos de monitoramento de notícias; pipelines com normalização e deduplicação estão nos repositórios Herez.
Scrapy
O que é: framework completo para crawling e scraping em escala, com gerenciamento de filas, middlewares e exportadores.
# Instalação
pip install scrapy
# myspider.py
import scrapy
class NewsSpider(scrapy.Spider):
name = 'news'
start_urls = ['https://example.com/news']
def parse(self, response):
for article in response.css('article'):
yield {
'title': article.css('h2 a::text').get(),
'link': article.css('h2 a::attr(href)').get()
}Executar: scrapy runspider myspider.py -o results.json
Contexto Herez: usado para crawlers periódicos com politeness, rotação de user agents e integração com pipelines de armazenamento; projetos completos estão nos repositórios Herez.
Selenium
O que é: automação de navegadores que permite renderizar páginas com JavaScript, preencher formulários e interagir com elementos dinâmicos.
# Instalação
pip install selenium
# requer driver do navegador (ex: chromedriver) compatível com a versão do navegador
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
options = Options()
options.add_argument('--headless')
driver = webdriver.Chrome(options=options)
driver.get('https://example.com/dynamic')
html = driver.page_source
soup = BeautifulSoup(html, 'lxml')
titles = [h.get_text(strip=True) for h in soup.select('.post-title')]
print(titles)
driver.quit()Contexto Herez: usado para páginas que carregam conteúdo via JavaScript e para fluxos autenticados; exemplos com login e captura de screenshots estão nos repositórios Herez.
lxml
O que é: parser rápido e robusto para HTML/XML com suporte a XPath e XSLT, ideal para extração precisa e performance.
# Instalação
pip install lxml
import requests
from lxml import html
resp = requests.get('https://example.com/catalog', timeout=10)
doc = html.fromstring(resp.content)
items = []
for node in doc.xpath('//div[@class="product"]'):
name = node.xpath('.//h3/text()')[0].strip()
price = node.xpath('.//span[@class="price"]/text()')[0].strip()
items.append({'name': name, 'price': price})
print(items)Contexto Herez: usado quando seletores CSS não são suficientes; pipelines com XPath e validação de schema estão nos repositórios Herez.
Boas práticas Herez para Web Scraping
- Respeite termos e robots.txt: verifique políticas do site e limite taxa de requisições para evitar bloqueios.
- Use headers e rotação de user agents: simule navegadores reais e evite padrões que disparem bloqueios.
- Cache e reuso: armazene páginas baixadas para evitar requisições repetidas durante desenvolvimento.
- Trate erros e retries: implemente backoff exponencial e logging para robustez.
- Proteja credenciais: nunca versionar senhas; use cofres de segredos para logins automatizados.
- Escalabilidade: para grandes volumes, prefira Scrapy com pipelines assíncronos e filas; monitore desempenho e custos.
- Repositórios Herez: exemplos completos, spiders, scripts de login e pipelines usados em projetos reais da Herez estão disponíveis nos repositórios GitHub e GitLab da Herez.
Comparação rápida
| Critério | Requests | BeautifulSoup | Scrapy | Selenium | lxml |
|---|---|---|---|---|---|
| Foco | HTTP | Parsing | Crawling | Automação navegador | Parsing rápido |
| Curva de aprendizado | Baixa | Baixa | Média | Média | Média |
| Ideal para | Páginas estáticas e APIs | Extração simples | Projetos em larga escala | Conteúdo dinâmico | Extração robusta com XPath |
Aspectos legais e éticos
Web scraping pode envolver restrições legais e de uso. Sempre verifique os termos do site, respeite limites técnicos e éticos, e prefira APIs oficiais quando disponíveis. Herez aplica revisão legal e políticas internas antes de executar crawlers em produção.
Último post da série
Este foi o último artigo e encerramos aqui a série sobre este resumo comparativo contendo um checklist de adoção para times que desejam padronizar bibliotecas Python em projetos de dados e engenharia.