-
Guia prático para escolher entre Estatística, Aprendizado de Máquina e Rede Neural: objetivos, tipo de previsão, volume de dados e recomendações
Como escolher o melhor modelo? — Métodos e critérios práticos Como escolher o melhor modelo? — Um guia prático Por Herez Moise Kattan • 13 de julho de 2026 Infográfico:
-
Enunciado completo do jogo Campo Minado (Minesweeper)
Jogo Campo Minado — Enunciado e Implementação | Herez Jogo Campo Minado Divulgação do enunciado: 02/05/2026 — Prazo de entrega: 27/06/2026 — Disciplina: Introdução ao desenvolvimento de jogos digitais e
-
Comandos Linux para gerenciar Memória e Processos
Comandos essenciais e exemplos práticos | Herez Comandos essenciais e exemplos práticos | Herez Post criado por Herez. Guia objetivo com explicação de comandos essenciais para administração de servidores e
-
Repositórios para aprender AI, Machine Learning, Deep Learning, NLP e Reinforcement Learning
Repositórios para aprender AI/ML — Herez Repositórios para aprender AI/ML Autor: Herez Este post reúne descrições práticas de repositórios que eu, Herez, utilizei para estudar inteligência artificial e aprendizado de
-
Comandos do Linux para Rede
Guia prático de comandos de rede Linux — Herez Guia prático de comandos de rede Linux Autor: Herez Este post reúne explicações objetivas de comandos essenciais para diagnóstico e administração
-
Guia Herez de comandos Git

Guia Herez de Comandos Git Completo PiadaMinha favorita: “Meu relacionamento com o Git é igual a um namoro: eu faço
commit, ele dápush, e quando aparece um conflito a gente termina e eu tentorevertara vida.”Foi boa vai; senão achou então uma segunda tentativa: “Por que o Git nunca perde a paciência? Porque ele sempre pode
stasharos problemas.”Resumo: referência prática dos comandos Git mais usados, com explicações e exemplos completos que a equipe Herez aplicou em projetos reais. Este post serve como checklist rápido e tutorial prático para desenvolvedores e times de engenharia.
Por que este guia importa
O Git é a base do fluxo de trabalho moderno de desenvolvimento. Conhecer os comandos essenciais e saber quando usá‑los reduz erros, acelera entregas e facilita colaboração. Abaixo você encontra os comandos organizados por categoria, exemplos práticos e scripts que a Herez usa em repositórios e pipelines.
Resumo rápido dos comandos
Categoria Comando O que faz Básicos git initCriar novo repositório Básicos git cloneCopiar repositório remoto Básicos git statusVer alterações pendentes Básicos git addAdicionar à área de preparação Básicos git commit -m "mensagem"Salvar alterações Sincronização git pullTrazer alterações remotas e mesclar Sincronização git pushEnviar commits ao remoto Sincronização git remote add <url>Conectar repositório local a remoto Sincronização git fetchBaixar alterações sem mesclar Branches git branchListar, criar ou excluir branches Branches git switch <nome>Mudar de branch Branches git merge <nome>Mesclar outra branch Branches git branch -d <nome>Excluir branch Avançado git log --oneline --graph --allHistórico resumido e visual Avançado git stashSalvar alterações temporariamente Avançado git stash popRestaurar alterações salvas Avançado git rebase <branch>Reaplicar commits para histórico limpo Avançado git cherry-pick <id-commit>Aplicar commit específico em outra branch Desfazer git restore <arquivo>Desfazer alterações em arquivo Desfazer git reset HEAD <arquivo>Remover arquivo da área de preparação Desfazer git revert <id-commit>Criar commit que reverte outro Ajuda git <comando> --helpVer manual do comando Comandos básicos com exemplos práticos
git init
O que faz: inicializa um repositório Git local.
mkdir meu-projeto cd meu-projeto git init # cria .git e prepara o repositório localExemplo Herez: usado para iniciar projetos internos de POCs; repositórios iniciais contêm README, .gitignore e pipeline CI mínimos.git clone
O que faz: clona um repositório remoto para sua máquina.
git clone git@servidor:herez/projeto.git cd projetoExemplo Herez: clonamos repositórios de templates para iniciar novos serviços com scripts de deploy prontos.git status
O que faz: mostra arquivos modificados, staged e não rastreados.
git status --short # M indica modificado, ?? indica não rastreadogit add
O que faz: adiciona alterações à área de preparação (staging).
git add arquivo.py git add . # adiciona todas as alteraçõesgit commit
O que faz: cria um commit com as alterações staged.
git commit -m "Corrige bug no parser de CSV"Exemplo Herez: mensagens padronizadas com prefixos (feat/, fix/, docs/) e uso de hooks para validar mensagens antes do commit.
Sincronização com repositórios remotos
git remote add
O que faz: adiciona um remoto ao repositório local.
git remote add origin git@servidor:herez/projeto.git git remote -vgit fetch
O que faz: baixa referências e objetos do remoto sem mesclar.
git fetch origin git log HEAD..origin/main --onelinegit pull
O que faz: busca e mescla alterações do remoto na branch atual.
git pull origin mainExemplo Herez: usamosgit pull --rebaseem pipelines locais para manter histórico linear antes de push.git push
O que faz: envia commits locais para o remoto.
git push origin feature/minha-feature # para criar upstream: git push -u origin feature/minha-feature
Trabalhando com branches
git branch
O que faz: listar, criar ou excluir branches.
git branch # lista branches locais git branch nova-branch # cria nova branch git branch -d antiga # exclui branch localgit switch
O que faz: muda para outra branch.
git switch nova-branch # alternativa antiga: git checkout nova-branchgit merge
O que faz: mescla outra branch na atual.
git switch main git merge feature/minha-featureExemplo Herez: mesclagens via pull request com revisão de código; merges fast‑forward evitados por política de equipe.git branch -d
O que faz: exclui branch local já mesclada.
git branch -d feature/minha-feature
Comandos avançados e fluxo limpo
git log –oneline –graph –all
O que faz: exibe histórico compacto e visual em árvore.
git log --oneline --graph --all --decorategit stash
O que faz: guarda alterações temporariamente sem commit.
git stash save "WIP: ajuste parser" git stash list git stash popExemplo Herez: usamos stash para trocar rapidamente de branch durante code review sem perder trabalho em andamento.git rebase
O que faz: reaplica commits sobre outra base para manter histórico linear.
git switch feature git fetch origin git rebase origin/main # resolver conflitos, depois: git rebase --continueExemplo Herez: rebase interativo (git rebase -i) para squash de commits antes de abrir PRs públicos.git cherry-pick
O que faz: aplica um commit específico em outra branch.
git switch hotfix git cherry-pick a1b2c3d4Exemplo Herez: cherry-pick usado para portar correções críticas para branches de release sem mesclar todo o trabalho em desenvolvimento.
Desfazer alterações com segurança
git restore
O que faz: desfaz alterações em arquivo (worktree).
git restore arquivo.txt # para restaurar versão do commit: git restore --source=HEAD~1 arquivo.txtgit reset HEAD
O que faz: remove arquivo da área de preparação sem perder alterações locais.
git reset HEAD arquivo.txtgit revert
O que faz: cria um novo commit que reverte outro commit (seguro para histórico público).
git revert a1b2c3d4 # cria commit que desfaz as mudanças do commit especificadoExemplo Herez: preferimosgit revertem branches compartilhadas para manter histórico auditável e evitar reescrita pública.
Ajuda e documentação
git <comando> –help
O que faz: exibe manual do comando com opções e exemplos.
git commit --help git --help --all
Boas práticas Herez para uso de Git
- Mensagens claras: use convenções (tipo: escopo — descrição) e ferramentas de lint para commits.
- Branches curtas: mantenha branches de feature pequenas e com PRs frequentes.
- Rebase local, não remoto: reescreva histórico apenas antes de compartilhar; evite rebase em branches públicas.
- Proteja branches principais: use políticas de merge, revisão obrigatória e CI verde antes de mergear.
- Automatize: hooks, CI e pipelines para testes, lint e deploy reduzem erros humanos.
- Documente: mantenha um CONTRIBUTING.md com fluxo Git recomendado pela equipe.
Observação Herez: todos os exemplos acima foram aplicados em projetos reais da Herez. Repositórios com scripts, hooks e pipelines de exemplo estão disponíveis nos repositórios internos da Herez para referência da equipe.Checklist rápido para operações comuns
- Iniciar projeto:
git init, criar.gitignore, primeiro commit. - Trabalhar em feature:
git switch -c feature/x, commits pequenos,git push -u origin feature/x. - Atualizar branch:
git fetch,git rebase origin/mainougit merge origin/mainconforme política. - Corrigir emergência:
git switch hotfix, aplicar correção,git cherry-pickse necessário. - Desfazer com segurança:
git revertpara histórico público;git resetougit restorepara trabalho local.
-
Bibliotecas Python para Web Scraping — Parte 6 da série de posts do Guia Herez
Web Scraping com Python — Guia Herez (Parte 6) Web Scraping com Python — Parte 6 da série Herez
Visão geral: esta é a sexta publicação da série Herez sobre bibliotecas Python. Aqui detalhamos as ferramentas essenciais para Web Scraping: Requests, BeautifulSoup, Scrapy, Selenium e lxml. Cada seção traz descrição, instalação, exemplos simples e completos de scraping usados em projetos reais por Herez. Exemplos e pipelines completos estão disponíveis nos repositórios GitHub e GitLab da Herez.
Publicado por Herez em
Como usar este post
Este guia apresenta cada biblioteca com exemplos práticos, incluindo scripts completos e reproduzíveis que Herez usou em projetos reais. Use os trechos para aprender a coletar dados de páginas estáticas e dinâmicas, montar crawlers e processar HTML/XML com XPath.
Resumo rápido
Biblioteca Função principal Quando usar Requests Requisições HTTP simples Páginas estáticas e APIs BeautifulSoup Parsing HTML fácil Extração de dados de HTML Scrapy Crawling e scraping em escala Projetos de coleta em larga escala Selenium Automação de navegador Páginas com JavaScript dinâmico lxml Parsing rápido com XPath Extração robusta e performance Bibliotecas detalhadas com exemplos completos
Requests
O que é: biblioteca simples e elegante para fazer requisições HTTP em Python.
# Instalação pip install requestsExemplo completo: baixar HTML e salvar localmenteimport requests url = 'https://example.com' resp = requests.get(url, timeout=10) if resp.status_code == 200: with open('example.html', 'w', encoding='utf-8') as f: f.write(resp.text) print('Página salva em example.html') else: print('Erro', resp.status_code)Contexto Herez: usado como etapa inicial em pipelines para baixar páginas antes de parse; scripts de download em lote estão nos repositórios Herez.
BeautifulSoup
O que é: parser de HTML que facilita navegar e extrair elementos do DOM com uma API intuitiva.
# Instalação pip install beautifulsoup4 # opcionalmente instalar lxml para performance pip install lxmlExemplo completo: extrair títulos e links de notíciasimport requests from bs4 import BeautifulSoup url = 'https://example.com/news' resp = requests.get(url, timeout=10) soup = BeautifulSoup(resp.text, 'lxml') articles = [] for item in soup.select('article h2 a'): title = item.get_text(strip=True) link = item['href'] articles.append({'title': title, 'link': link}) print(articles)Contexto Herez: usado em projetos de monitoramento de notícias; pipelines com normalização e deduplicação estão nos repositórios Herez.
Scrapy
O que é: framework completo para crawling e scraping em escala, com gerenciamento de filas, middlewares e exportadores.
# Instalação pip install scrapyExemplo completo: spider simples para coletar títulos# myspider.py import scrapy class NewsSpider(scrapy.Spider): name = 'news' start_urls = ['https://example.com/news'] def parse(self, response): for article in response.css('article'): yield { 'title': article.css('h2 a::text').get(), 'link': article.css('h2 a::attr(href)').get() }Executar:
scrapy runspider myspider.py -o results.jsonContexto Herez: usado para crawlers periódicos com politeness, rotação de user agents e integração com pipelines de armazenamento; projetos completos estão nos repositórios Herez.
Selenium
O que é: automação de navegadores que permite renderizar páginas com JavaScript, preencher formulários e interagir com elementos dinâmicos.
# Instalação pip install selenium # requer driver do navegador (ex: chromedriver) compatível com a versão do navegadorExemplo completo: extrair conteúdo renderizadofrom selenium import webdriver from selenium.webdriver.chrome.options import Options from bs4 import BeautifulSoup options = Options() options.add_argument('--headless') driver = webdriver.Chrome(options=options) driver.get('https://example.com/dynamic') html = driver.page_source soup = BeautifulSoup(html, 'lxml') titles = [h.get_text(strip=True) for h in soup.select('.post-title')] print(titles) driver.quit()Contexto Herez: usado para páginas que carregam conteúdo via JavaScript e para fluxos autenticados; exemplos com login e captura de screenshots estão nos repositórios Herez.
lxml
O que é: parser rápido e robusto para HTML/XML com suporte a XPath e XSLT, ideal para extração precisa e performance.
# Instalação pip install lxmlExemplo completo: extrair dados com XPathimport requests from lxml import html resp = requests.get('https://example.com/catalog', timeout=10) doc = html.fromstring(resp.content) items = [] for node in doc.xpath('//div[@class="product"]'): name = node.xpath('.//h3/text()')[0].strip() price = node.xpath('.//span[@class="price"]/text()')[0].strip() items.append({'name': name, 'price': price}) print(items)Contexto Herez: usado quando seletores CSS não são suficientes; pipelines com XPath e validação de schema estão nos repositórios Herez.
Boas práticas Herez para Web Scraping
- Respeite termos e robots.txt: verifique políticas do site e limite taxa de requisições para evitar bloqueios.
- Use headers e rotação de user agents: simule navegadores reais e evite padrões que disparem bloqueios.
- Cache e reuso: armazene páginas baixadas para evitar requisições repetidas durante desenvolvimento.
- Trate erros e retries: implemente backoff exponencial e logging para robustez.
- Proteja credenciais: nunca versionar senhas; use cofres de segredos para logins automatizados.
- Escalabilidade: para grandes volumes, prefira Scrapy com pipelines assíncronos e filas; monitore desempenho e custos.
- Repositórios Herez: exemplos completos, spiders, scripts de login e pipelines usados em projetos reais da Herez estão disponíveis nos repositórios GitHub e GitLab da Herez.
Dica Herez: comece com Requests + BeautifulSoup para páginas estáticas; adicione Selenium para páginas dinâmicas; migre para Scrapy quando precisar de crawling em escala.Comparação rápida
Critério Requests BeautifulSoup Scrapy Selenium lxml Foco HTTP Parsing Crawling Automação navegador Parsing rápido Curva de aprendizado Baixa Baixa Média Média Média Ideal para Páginas estáticas e APIs Extração simples Projetos em larga escala Conteúdo dinâmico Extração robusta com XPath Aspectos legais e éticos
Web scraping pode envolver restrições legais e de uso. Sempre verifique os termos do site, respeite limites técnicos e éticos, e prefira APIs oficiais quando disponíveis. Herez aplica revisão legal e políticas internas antes de executar crawlers em produção.
Último post da série
Este foi o último artigo e encerramos aqui a série sobre este resumo comparativo contendo um checklist de adoção para times que desejam padronizar bibliotecas Python em projetos de dados e engenharia.
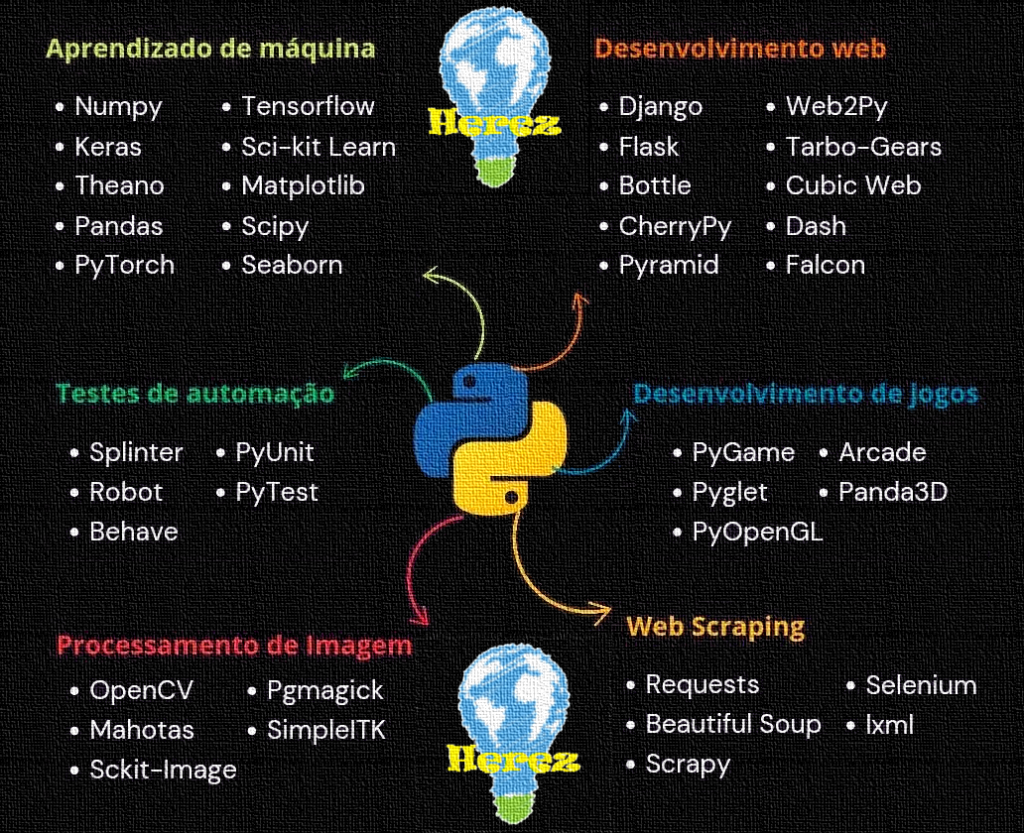
-
Bibliotecas Python para Desenvolvimento de jogos — Parte 5 da série de posts do Guia Herez
Desenvolvimento de Jogos em Python — Guia Herez (Parte 5) Desenvolvimento de Jogos em Python — Parte 5 da série Herez
Visão geral: esta é a quinta publicação da série Herez sobre bibliotecas Python. Aqui detalhamos as ferramentas mais usadas para criar jogos em Python: PyGame, Pyglet, PyOpenGL, Arcade e Panda3D. Cada seção traz descrição, motivos para usar, instalação, exemplos de uso e um jogo simples completo que foi aplicado em projetos reais da Herez. Os projetos e exemplos completos estão disponíveis nos repositórios GitHub e GitLab da Herez.
Publicado por Herez em
Como usar este post
Use este guia para escolher a biblioteca certa, copiar trechos de código e rodar jogos simples localmente. Todos os exemplos foram testados em projetos reais da Herez; os repositórios contêm código-fonte, assets e instruções de execução.
Resumo rápido
Biblioteca Foco Quando usar PyGame 2D clássico Jogos 2D, protótipos e ensino Pyglet 2D/3D leve Aplicações multimídia e OpenGL direto PyOpenGL OpenGL puro Gráficos 3D customizados e engines Arcade 2D moderno Jogos 2D com API simples e performance Panda3D 3D completo Jogos 3D, simulações e aplicações interativas Bibliotecas detalhadas com jogos simples completos
PyGame
O que é: biblioteca clássica para desenvolvimento de jogos 2D em Python, com suporte a gráficos, som, entrada e temporização.
# Instalação pip install pygameJogo simples completo: “Catch the Ball” (PyGame)import pygame, random, sys pygame.init() W, H = 640, 480 screen = pygame.display.set_mode((W,H)) clock = pygame.time.Clock() player = pygame.Rect(W//2-25, H-60, 50, 50) balls = [] score = 0 FONT = pygame.font.SysFont(None, 36) while True: for e in pygame.event.get(): if e.type == pygame.QUIT: pygame.quit(); sys.exit() keys = pygame.key.get_pressed() if keys[pygame.K_LEFT]: player.x -= 5 if keys[pygame.K_RIGHT]: player.x += 5 if random.random() < 0.02: balls.append(pygame.Rect(random.randint(0,W-20), -20, 20, 20)) for b in balls[:]: b.y += 5 if b.colliderect(player): score += 1; balls.remove(b) elif b.y > H: balls.remove(b) screen.fill((30,30,40)) pygame.draw.rect(screen, (200,50,50), player) for b in balls: pygame.draw.ellipse(screen, (50,200,50), b) screen.blit(FONT.render(f'Score: {score}', True, (255,255,255)), (10,10)) pygame.display.flip() clock.tick(60)Contexto Herez: versão usada em workshops internos para ensinar game loop, colisões e input; projeto completo com assets e testes está nos repositórios Herez.
Pyglet
O que é: biblioteca leve para multimídia e jogos, com integração direta a OpenGL e suporte a áudio, janelas e eventos.
# Instalação pip install pygletJogo simples completo: “Asteroid Lite” (Pyglet)import pyglet, random window = pyglet.window.Window(640,480) batch = pyglet.graphics.Batch() player = pyglet.shapes.Rectangle(300,20,40,40,color=(50,150,255),batch=batch) asteroids = [] label = pyglet.text.Label('Score: 0', x=10, y=450) score = 0 @window.event def on_draw(): window.clear() batch.draw() label.draw() def update(dt): global score if random.random() < 0.02: asteroids.append(pyglet.shapes.Circle(random.randint(0,640),480,10,color=(200,50,50),batch=batch)) for a in asteroids[:]: a.y -= 200*dt if a.y < 0: asteroids.remove(a) a.delete() if a.x > player.x and a.x < player.x+40 and a.y < 60: score += 1 asteroids.remove(a) a.delete() label.text = f'Score: {score}' pyglet.clock.schedule_interval(update, 1/60.0) pyglet.app.run()Contexto Herez: usado em protótipos que exigiam integração OpenGL simples; código e variações estão nos repositórios Herez.
PyOpenGL
O que é: bindings Python para OpenGL, permitindo controle direto do pipeline gráfico para criar gráficos 3D customizados.
# Instalação pip install PyOpenGL PyOpenGL_accelerateJogo simples completo: "Rotating Triangle" (PyOpenGL)from OpenGL.GL import * from OpenGL.GLUT import * angle = 0.0 def display(): global angle glClear(GL_COLOR_BUFFER_BIT|GL_DEPTH_BUFFER_BIT) glLoadIdentity() glRotatef(angle, 0, 0, 1) glBegin(GL_TRIANGLES) glColor3f(1,0,0); glVertex2f(0,0.6) glColor3f(0,1,0); glVertex2f(-0.6,-0.6) glColor3f(0,0,1); glVertex2f(0.6,-0.6) glEnd() glutSwapBuffers() angle += 0.5 glutInit() glutInitDisplayMode(GLUT_DOUBLE | GLUT_RGBA) glutInitWindowSize(600,600) glutCreateWindow(b'Rotating Triangle') glutDisplayFunc(display) glutIdleFunc(display) glutMainLoop()Contexto Herez: usado para prototipar shaders e efeitos gráficos; exemplos de integração com engines estão nos repositórios Herez.
Arcade
O que é: biblioteca moderna para jogos 2D com API simples, boa performance e integração com OpenGL via pyglet.
# Instalação pip install arcadeJogo simples completo: "Space Shooter" (Arcade)import arcade SCREEN_W, SCREEN_H = 800, 600 class MyGame(arcade.Window): def __init__(self): super().__init__(SCREEN_W, SCREEN_H, "Space Shooter") self.player = arcade.SpriteSolidColor(50,30,arcade.color.BLUE) self.player.center_x = SCREEN_W//2; self.player.center_y = 50 self.bullets = arcade.SpriteList() def on_draw(self): arcade.start_render() self.player.draw() self.bullets.draw() def on_update(self, dt): self.bullets.update() for b in self.bullets: b.center_y += 5 if b.center_y > SCREEN_H: b.kill() def on_key_press(self, key, modifiers): if key == arcade.key.SPACE: bullet = arcade.SpriteSolidColor(5,10,arcade.color.YELLOW) bullet.center_x = self.player.center_x; bullet.center_y = self.player.center_y+20 self.bullets.append(bullet) if __name__ == '__main__': game = MyGame() arcade.run()Contexto Herez: usado para protótipos educacionais e jogos 2D com física simples; projetos completos com assets estão nos repositórios Herez.
Panda3D
O que é: engine 3D completa com renderização, física básica, sistema de cenas e ferramentas para jogos e simulações interativas.
# Instalação pip install panda3dJogo simples completo: "3D Spinner" (Panda3D)from direct.showbase.ShowBase import ShowBase from panda3d.core import AmbientLight, DirectionalLight class MyApp(ShowBase): def __init__(self): super().__init__() self.scene = self.loader.loadModel('models/box') self.scene.reparentTo(self.render) self.scene.setPos(0, 10, 0) self.taskMgr.add(self.spin, 'spinTask') def spin(self, task): self.scene.setH(task.time * 60 % 360) return task.cont app = MyApp() app.run()Contexto Herez: usado em protótipos 3D e simulações interativas; cenas, modelos e scripts de build estão nos repositórios Herez.
Comparação prática
Critério PyGame Arcade Pyglet / PyOpenGL Panda3D Foco 2D clássico 2D moderno Multimídia / OpenGL 3D engine completa Curva de aprendizado Baixa Baixa Média Média a alta Ideal para Educação e protótipos Jogos 2D com performance Gráficos customizados Jogos 3D e simulações Escalabilidade Média Média Alta (com OpenGL) Alta Boas práticas Herez para desenvolvimento de jogos em Python
- Comece simples: valide mecânicas com um protótipo 2D antes de investir em 3D.
- Organize assets: mantenha sprites, sons e níveis em pastas versionadas; use formatos otimizados para deploy.
- Ambientes e dependências: use ambientes virtuais e registre versões em
requirements.txtpara reprodutibilidade. - Performance: profile o jogo; mova lógica crítica para C/C++ ou use bibliotecas aceleradas quando necessário.
- Testes e CI: automatize testes de integração e builds; inclua smoke tests que executem o loop principal por alguns frames.
- Repositórios Herez: jogos completos, assets e instruções de execução usados em projetos reais da Herez estão disponíveis nos repositórios GitHub e GitLab da Herez.
Dica Herez: para aprender rápido, implemente o jogo "Catch the Ball" em PyGame e depois reimplemente em Arcade para comparar APIs e performance.Próximo post da série
No próximo artigo cobriremos bibliotecas Python para Web Scraping, com exemplos práticos, estratégias éticas e pipelines para transformar dados brutos em insights.
Biografia do autor: Doutor Herez possui Bacharelado em Análise de Sistemas, Mestrado em Engenharia de Computação/Software, Doutorado em Ciência da Computação e seu primeiro diploma acadêmico em Processamento de Dados em 1996. Início profissional na carreira em T.I. em 1993 com o primeiro certificado de programação de computadores em 1986 e início da participação em curso de programação em 1985. Microsoft Certified Professional desde 2000, entre outros títulos oficiais de diversos grandes fabricantes internacionais de software, também criou cursos e provas oficiais voltados à programação de computadores. Tem experiência na área de Ciência da Computação, com ênfase em Engenharia de Software, atuando principalmente nos seguintes temas: análise e desenvolvimento de sistemas, engenharia de software, métodos de pesquisa e métodos ágeis.