-
Bibliotecas Python para Processamento de imagem — Parte 3 da série de posts do Guia Herez
Processamento de Imagens em Python — Guia Herez (Parte 3) Processamento de Imagens em Python — Parte 3 da série Herez Visão geral: esta é a terceira publicação da série
-
Bibliotecas Python para Testes Automatizados — Parte 2 da série de posts do Guia Herez
Testes Automatizados em Python — Guia Herez (Parte 2) Testes Automatizados em Python — Parte 2 da série Herez Visão geral: esta é a segunda publicação da série Herez sobre
-
Bibliotecas Python para Aprendizado de Máquina — Parte 1 da série de posts do Guia Herez
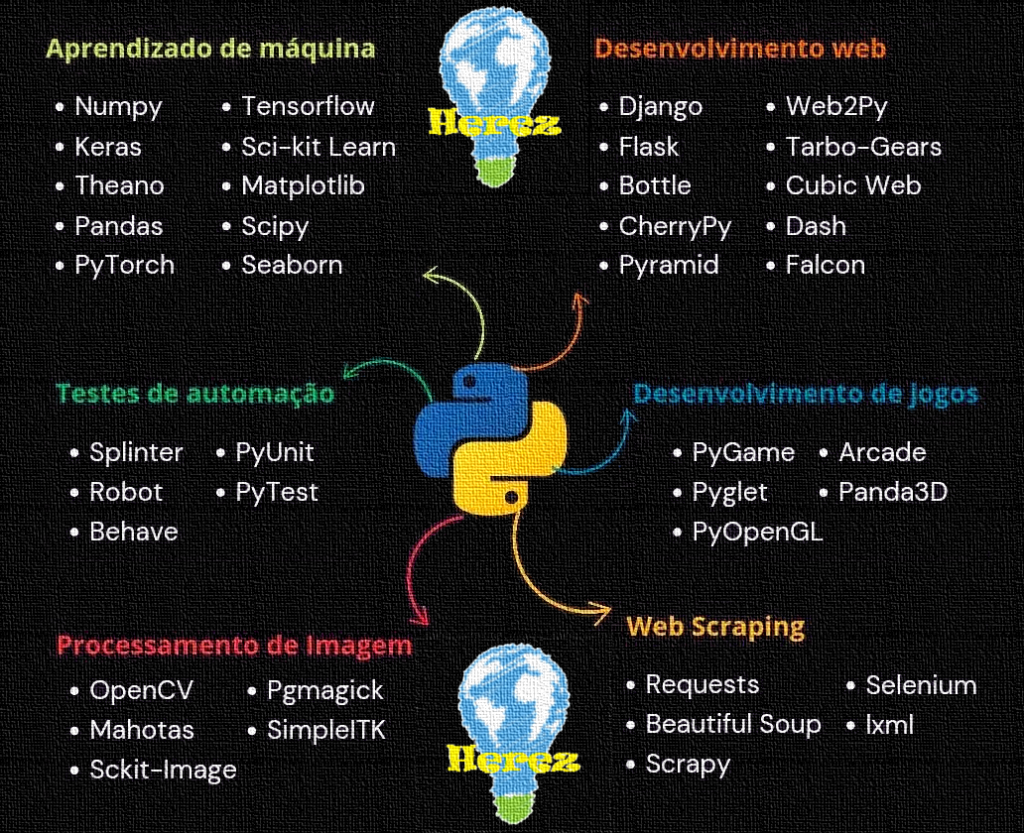
Bibliotecas Python para Aprendizado de Máquina — Guia Herez Bibliotecas Python para Aprendizado de Máquina — Parte 1 da série de posts do Guia Herez Visão geral: existem muitas bibliotecas
-
Guia prático Herez sobre os diretórios essenciais do Linux com explicações e exemplos
Diretórios essenciais do Linux: /home /etc /var /usr /bin /sbin /boot /lib /dev /proc Diretórios essenciais do Linux Resumo: este post explica por que o Linux é um sistema operacional
-
A four-minute video introduction covering workflow, the Cynefin framework, and the RUT matrix
Developers often prefer a pull workflow because it allows them to select the tasks they want to work on. However, when a project is well-planned and clearly defined, the workflow
-
Bibliotecas Python para Desenvolvimento Web — Parte 4 da série de posts do Guia Herez
Desenvolvimento Web em Python — Guia Herez Parte 4 Desenvolvimento Web em Python — Parte 4 da série Herez
Visão geral: esta é a quarta publicação da série Herez sobre bibliotecas Python. Aqui detalhamos frameworks e microframeworks para desenvolvimento web: Django, Flask, Bottle, CherryPy, Pyramid, Web2py, TurboGears, CubicWeb, Dash e Falcon. Cada seção traz descrição, motivos para usar, instalação e exemplos práticos aplicados em projetos reais da Herez. Exemplos completos estão disponíveis nos repositórios GitHub e GitLab da Herez.
Publicado por Herez em
Como usar este post
Use este guia para comparar frameworks, escolher a ferramenta certa para seu projeto e copiar trechos de código que aceleram a prototipagem. Todos os exemplos foram aplicados em projetos reais da Herez e os repositórios contêm aplicações completas, scripts de deploy e testes.
Resumo rápido
Framework Tipo Quando usar Django Full stack Aplicações completas com admin e ORM Flask Microframework APIs e serviços leves Bottle Microframework APIs pequenas e protótipos CherryPy Microframework Serviços embutidos e servidores simples Pyramid Flexível Projetos que crescem em complexidade Web2py Full stack Aplicações com foco em produtividade TurboGears Full stack Aplicações modulares e escaláveis CubicWeb Framework semântico Aplicações baseadas em dados e ontologias Dash Visualização Dashboards interativos e data apps Falcon Microframework APIs de alta performance Frameworks detalhados com exemplos reais
Django
O que é: framework full stack com ORM, sistema de templates, painel administrativo e convenções que aceleram desenvolvimento de aplicações completas.
Por que usar: produtividade alta, segurança integrada e ecossistema maduro para autenticação, internacionalização e deploy.
# Instalação pip install djangoExemplo prático# views.py from django.shortcuts import render from .models import Article def index(request): articles = Article.objects.order_by('-published')[:10] return render(request, 'blog/index.html', {'articles': articles})Contexto Herez: usado em portal de conteúdo com CMS customizado; o admin do Django foi estendido para workflows editoriais. Código e scripts de deploy estão nos repositórios Herez.
Flask
O que é: microframework minimalista que fornece roteamento, templates e extensões para adicionar funcionalidades conforme necessário.
# Instalação pip install flaskExemplo práticofrom flask import Flask, jsonify, request app = Flask(__name__) @app.route('/api/predict', methods=['POST']) def predict(): data = request.json result = model.predict(data['features']) return jsonify({'prediction': result.tolist()})Contexto Herez: microserviço de inferência para modelos de ML; containerizado e integrado ao gateway de API da Herez.
Bottle
O que é: microframework de um único arquivo, ideal para protótipos, demos e APIs muito pequenas.
# Instalação pip install bottleExemplo práticofrom bottle import route, run, request, response @route('/hello') def hello(): return "Hello from Bottle" run(host='0.0.0.0', port=8080)Contexto Herez: usado em protótipos rápidos e ferramentas internas; exemplos de scripts estão nos repositórios Herez.
CherryPy
O que é: framework minimalista que inclui servidor HTTP embutido, ideal para serviços autônomos e aplicações que precisam de controle fino do servidor.
# Instalação pip install cherrypyExemplo práticoimport cherrypy class Hello: @cherrypy.expose def index(self): return "Hello CherryPy" cherrypy.quickstart(Hello())Contexto Herez: serviço interno de processamento de arquivos com servidor embutido; configuração de threads e logging ajustada para produção.
Pyramid
O que é: framework flexível que permite começar pequeno e crescer; suporta diferentes estilos de roteamento e autenticação.
# Instalação pip install pyramidExemplo práticofrom pyramid.config import Configurator from pyramid.response import Response def hello_world(request): return Response('Hello Pyramid') if __name__ == '__main__': with Configurator() as config: config.add_route('hello', '/') config.add_view(hello_world, route_name='hello') app = config.make_wsgi_app()Contexto Herez: usado em projetos que exigem migração incremental de monólitos para serviços modulares; exemplos de configuração e testes estão nos repositórios Herez.
Web2py
O que é: framework full stack com foco em produtividade e segurança, inclui IDE web e ferramentas integradas.
# Instalação pip install web2pyExemplo prático# controller default.py def index(): rows = db(db.article).select(orderby=~db.article.created_on) return dict(rows=rows)Contexto Herez: protótipos de aplicações internas e ferramentas administrativas; exemplos de modelos e controllers estão nos repositórios Herez.
TurboGears
O que é: framework full stack modular que combina componentes para criar aplicações escaláveis e organizadas.
# Instalação pip install TurboGears2Exemplo prático# controller example from tg import expose, TGController class RootController(TGController): @expose('json') def index(self): return {'status': 'ok'}Contexto Herez: aplicações modulares com camadas separadas de serviço e apresentação; padrões de projeto e testes disponíveis nos repositórios Herez.
CubicWeb
O que é: framework orientado a dados e semântico, ideal para aplicações que modelam domínios complexos e ontologias.
# Instalação pip install cubicwebExemplo prático# esquema e views são definidos por componentes; exemplo simplificado # define entidades e relações, depois gere views automaticamenteContexto Herez: usado em projetos de catalogação de dados e repositórios semânticos; modelos e scripts de ingestão estão nos repositórios Herez.
Dash
O que é: framework para construir dashboards interativos e aplicações de visualização de dados com componentes reativos.
# Instalação pip install dashExemplo práticoimport dash from dash import html, dcc import plotly.express as px app = dash.Dash(__name__) df = px.data.iris() fig = px.scatter(df, x='sepal_width', y='sepal_length', color='species') app.layout = html.Div([ dcc.Graph(figure=fig) ]) if __name__ == '__main__': app.run_server(debug=True)Contexto Herez: dashboards de monitoramento de modelos e painéis de métricas; aplicações com autenticação e deploy em containers estão nos repositórios Herez.
Falcon
O que é: microframework focado em performance para construir APIs REST de alta velocidade.
# Instalação pip install falconExemplo práticoimport falcon import json class Resource: def on_get(self, req, resp): resp.media = {'status': 'ok'} app = falcon.App() app.add_route('/health', Resource())Contexto Herez: APIs de baixa latência para serviços de autenticação e ingestão; exemplos de integração com gateways e testes de carga estão nos repositórios Herez.
Comparação prática
Critério Django Flask Pyramid Dash Foco Full stack Microframework Flexível Dashboards Curva de aprendizado Média Baixa Média Baixa Ideal para Portais e aplicações completas APIs e microserviços Projetos que crescem Visualização e data apps Escalabilidade Alta Alta com arquitetura adequada Alta Média Boas práticas Herez para desenvolvimento web
- Escolha pelo escopo: use Django para aplicações completas; Flask ou Falcon para APIs; Dash para dashboards interativos.
- Arquitetura: separe apresentação, lógica e persistência; prefira microserviços quando precisar escalar independentemente.
- Segurança: valide entradas, use HTTPS, proteja endpoints e gerencie segredos com cofre de segredos.
- CI/CD: automatize testes, linting e deploy; inclua testes de integração e smoke tests para cada release.
- Repositórios Herez: exemplos completos, templates de projeto e pipelines de CI usados em projetos reais da Herez estão disponíveis nos repositórios GitHub e GitLab da Herez.
Dica Herez: comece com um protótipo mínimo em Flask para validar requisitos; se o projeto crescer, avalie migrar para Django ou compor microserviços com Falcon para endpoints críticos de performance.Próximo post da série
No próximo artigo cobriremos bibliotecas Python para Web Scraping com exemplos práticos, estratégias de coleta ética e pipelines para transformar dados brutos em insights.
-
Bibliotecas Python para Processamento de imagem — Parte 3 da série de posts do Guia Herez
Processamento de Imagens em Python — Guia Herez (Parte 3) Processamento de Imagens em Python — Parte 3 da série Herez
Visão geral: esta é a terceira publicação da série Herez sobre bibliotecas Python. Aqui detalhamos OpenCV, Mahotas, scikit-image, pgmagick e SimpleITK, com exemplos práticos usados em projetos reais por Herez. Esses exemplos e outros projetos estão disponíveis nos repositórios GitHub e GitLab da Herez.
Publicado por Herez em
Como usar este post
Cada seção traz: descrição, por que usar, instalação, exemplo prático e contexto de projeto. Os trechos de código são reproduzíveis e foram aplicados em projetos reais da Herez; os repositórios contêm notebooks e pipelines completos.
Resumo rápido
Biblioteca Função principal Quando usar OpenCV Visão computacional e processamento em tempo real Detecção, tracking, transformações e pipelines de CV Mahotas Operações de imagem rápidas em C++ Filtragem, morfologia e extração de features scikit-image Algoritmos de processamento e análise de imagem Segmentação, filtros e transformadas científicas pgmagick Bindings para GraphicsMagick Manipulação avançada e conversão de imagens SimpleITK Processamento de imagens médicas Registro, segmentação e análise volumétrica Bibliotecas detalhadas com exemplos reais
OpenCV
O que é: biblioteca abrangente para visão computacional e processamento de imagens, otimizada para desempenho e uso em tempo real.
Por que usar: algoritmos prontos para detecção de objetos, reconhecimento facial, transformações geométricas, calibração de câmeras e tracking; integração direta com C++/Python para produção.
# Instalação pip install opencv-pythonExemplo prático (detecção de bordas e contornos)import cv2 img = cv2.imread('input.jpg', cv2.IMREAD_GRAYSCALE) blur = cv2.GaussianBlur(img, (5,5), 0) edges = cv2.Canny(blur, 50, 150) contours, _ = cv2.findContours(edges, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) cv2.drawContours(img, contours, -1, (255,0,0), 2) cv2.imwrite('contours.jpg', img)Contexto Herez: usado em projeto de inspeção visual para detectar defeitos em peças industriais; pipeline em produção disponível nos repositórios Herez.
Mahotas
O que é: biblioteca de processamento de imagens com implementações em C++ para desempenho, oferecendo filtros, morfologia e extração de features.
# Instalação pip install mahotasExemplo prático (extração de features Haralick)import mahotas as mh import numpy as np img = mh.imread('input.png', as_grey=True) textures = mh.features.haralick(img).mean(axis=0) print('Haralick features:', textures)Contexto Herez: extração de descritores para classificação de texturas em imagens de satélite; versão otimizada em C++ integrada ao pipeline de análise.
scikit-image
O que é: coleção de algoritmos de processamento e análise de imagem em Python, com foco em clareza e integração com NumPy/SciPy.
# Instalação pip install scikit-imageExemplo prático (segmentação por Otsu e remoção de ruído)from skimage import io, filters, morphology img = io.imread('input.jpg', as_gray=True) denoised = filters.gaussian(img, sigma=1) th = filters.threshold_otsu(denoised) mask = denoised > th clean = morphology.remove_small_objects(mask, min_size=500) io.imsave('segmented.png', clean.astype('uint8')*255)Contexto Herez: usado em projetos de análise de imagens biológicas para segmentar células; notebooks com experimentos estão nos repositórios Herez.
pgmagick
O que é: bindings Python para GraphicsMagick, permitindo manipulação avançada de imagens, conversão de formatos e operações de alta qualidade.
# Instalação (pode requerer dependências do sistema) pip install pgmagickExemplo prático (redimensionamento e otimização para web)from pgmagick import Image img = Image('input.tif') img.resize('800x600') img.quality(85) img.write('output.jpg')Contexto Herez: pipeline de geração de thumbnails e otimização de imagens para portais de conteúdo; scripts de conversão em lote disponíveis nos repositórios Herez.
SimpleITK
O que é: toolkit focado em imagens médicas, com suporte a DICOM, registro, segmentação e análise volumétrica; projetado para pesquisa e aplicações clínicas.
# Instalação pip install SimpleITKExemplo prático (registro rígido entre duas imagens médicas)import SimpleITK as sitk fixed = sitk.ReadImage('fixed.nii') moving = sitk.ReadImage('moving.nii') initial_transform = sitk.CenteredTransformInitializer(fixed, moving, sitk.Euler3DTransform()) registration = sitk.ImageRegistrationMethod() registration.SetMetricAsMeanSquares() registration.SetOptimizerAsRegularStepGradientDescent(learningRate=1.0, minStep=1e-6, numberOfIterations=200) registration.SetInitialTransform(initial_transform, inPlace=False) final_transform = registration.Execute(fixed, moving) resampled = sitk.Resample(moving, fixed, final_transform, sitk.sitkLinear, 0.0, moving.GetPixelID()) sitk.WriteImage(resampled, 'registered.nii')Contexto Herez: aplicado em projeto de análise de imagens médicas para alinhar séries temporais; pipelines e exemplos clínicos estão documentados nos repositórios Herez.
Comparação prática e recomendações Herez
Critério OpenCV scikit-image Mahotas pgmagick SimpleITK Foco Visão computacional Pesquisa e algoritmos Desempenho C++ Manipulação/GraphicsMagick Imagens médicas Desempenho Alto Médio Alto Médio Alto (volumétrico) Curva de aprendizado Média Baixa a média Média Média Média Ideal para Tempo real e produção Prototipagem científica Operações intensivas em CPU Conversão e qualidade Pesquisa clínica e diagnóstico Boas práticas Herez
- Combine ferramentas: use OpenCV para etapas em tempo real e scikit-image/Mahotas para análise científica e extração de features.
- Ambientes isolados: crie ambientes virtuais (
venvouconda) e registre versões emrequirements.txtpara reprodutibilidade. - Documente dependências nativas: automatize instalação de bibliotecas do sistema para pgmagick e SimpleITK no CI.
- Valide com métricas: use IoU, Dice, PSNR e SSIM para avaliar qualidade antes de produção.
- Repositórios Herez: exemplos completos, notebooks e pipelines usados em projetos reais por Herez estão disponíveis nos repositórios GitHub e GitLab da Herez.
Dica Herez: comece prototipando com scikit-image e OpenCV; quando a performance for crítica, migre partes para Mahotas ou implementações C++ e mantenha testes automatizados para garantir qualidade.Próximo post da série
No próximo artigo cobriremos bibliotecas Python para Web Scraping, com exemplos práticos, estratégias de coleta ética e pipelines para transformar dados brutos em insights.
-
Bibliotecas Python para Testes Automatizados — Parte 2 da série de posts do Guia Herez
Testes Automatizados em Python — Guia Herez (Parte 2) Testes Automatizados em Python — Parte 2 da série Herez
Visão geral: esta é a segunda publicação da série Herez sobre bibliotecas Python. Aqui abordamos ferramentas para testes automatizados: Splinter, Robot Framework, Behave, PyUnit (unittest) e PyTest. O objetivo é oferecer descrições práticas, comandos de instalação e cenários de uso para escolher a ferramenta certa para seu projeto.
Publicado por Herez em
Como usar este post
Cada seção descreve a biblioteca, por que usá‑la, comando de instalação e exemplos de casos de uso. Use este guia para comparar ferramentas e montar um fluxo de testes automatizados adequado ao seu time e produto.
Resumo rápido
Biblioteca Tipo Quando usar Splinter Automação de navegador (wrapper) Testes de UI simples; alternativa a Selenium Robot Framework Framework de automação baseado em palavras-chave Testes de aceitação, RPA e automação de alto nível Behave BDD (Behavior Driven Development) Especificações executáveis em Gherkin PyUnit / unittest Framework de testes padrão Testes unitários com estilo xUnit PyTest Framework de testes moderno Testes unitários, integração e parametrizados; extensível Bibliotecas detalhadas
Splinter
O que é: biblioteca que simplifica a automação de navegadores, oferecendo uma API de alto nível que pode usar drivers como Selenium, zope.testbrowser ou outros backends.
Por que usar: ideal para escrever testes de interface web com menos boilerplate que o Selenium puro; facilita ações comuns (clicar, preencher formulários, navegar) em testes de aceitação.
# Instalação pip install splinterCasos de uso: testes de fluxo de usuário em aplicações web, validação de formulários, smoke tests de UI e automação de tarefas simples no navegador.
Robot Framework
O que é: framework de automação baseado em palavras‑chave, orientado a testes de aceitação e automação de processos (RPA). Fornece sintaxe legível por humanos e integrações com bibliotecas externas.
Por que usar: excelente para equipes que preferem escrever casos de teste em formato tabular/keyword-driven; facilita colaboração entre desenvolvedores, QA e stakeholders não técnicos.
# Instalação pip install robotframeworkCasos de uso: testes de aceitação, automação de processos repetitivos, integração com Selenium para testes de UI e cenários de RPA.
Behave
O que é: framework para BDD (Behavior Driven Development) que usa a linguagem Gherkin para descrever comportamentos em cenários legíveis (Given/When/Then).
Por que usar: quando você quer alinhar requisitos e testes com stakeholders, transformando especificações em cenários executáveis que servem como documentação viva.
# Instalação pip install behaveCasos de uso: especificação e validação de requisitos, testes de aceitação automatizados e colaboração entre times de produto e QA.
PyUnit / unittest
O que é: implementação em Python do estilo xUnit, incluída na biblioteca padrão como
unittest(historicamente conhecida como PyUnit).Por que usar: disponível por padrão, com estrutura familiar (TestCase, setUp, tearDown) e compatibilidade com muitas ferramentas e runners.
# Uso básico (não requer instalação) python -m unittest discoverCasos de uso: testes unitários clássicos, integração com CI e projetos que preferem dependências mínimas e API xUnit tradicional.
PyTest
O que é: framework de testes moderno e amplamente adotado, conhecido por sintaxe simples, fixtures poderosas e ecossistema de plugins.
Por que usar: reduz boilerplate, suporta parametrização, fixtures reutilizáveis e integrações com ferramentas de cobertura e mocks; é frequentemente recomendado como primeira escolha para novos projetos Python.
# Instalação pip install pytestCasos de uso: testes unitários, testes de integração, testes parametrizados, TDD e pipelines de CI. PyTest é frequentemente escolhido por sua simplicidade e extensibilidade.
Comparação rápida
Critério Splinter Robot Framework Behave unittest (PyUnit) PyTest Foco Automação de navegador Keyword-driven / RPA BDD Unitário (xUnit) Unitário/Integração Curva de aprendizado Baixa Média Média Baixa Baixa Ideal para QA de UI Times multidisciplinares Alinhamento com produto Projetos padrão Projetos modernos e TDD Extensibilidade Média Alta Média Média Alta (plugins) Boas práticas para testes automatizados
- Separe testes por camadas: unitários, integração e aceitação.
- Use ambientes isolados e dados de teste controlados; evite dependências externas nos testes unitários.
- Automatize execução em CI e gere relatórios de cobertura e falhas.
- Prefira PyTest para novos projetos, mantendo compatibilidade com
unittestquando necessário. - Use Robot ou Behave quando stakeholders não técnicos precisarem ler ou escrever cenários de teste.
Dica Herez: comece com PyTest para criar uma base sólida; adicione Robot ou Behave apenas quando houver necessidade clara de testes de aceitação legíveis por não desenvolvedores.Próximo post da série
No próximo artigo cobriremos bibliotecas Python para Processamento de Imagens (Pillow, OpenCV, scikit-image), com exemplos práticos de pipelines de pré‑processamento e análise.
Biografia do autor: Doutor Herez possui Bacharelado em Análise de Sistemas, Mestrado em Engenharia de Computação/Software, Doutorado em Ciência da Computação e seu primeiro diploma acadêmico em Processamento de Dados em 1996. Início profissional na carreira em T.I. em 1993 com o primeiro certificado de programação de computadores em 1986 e início da participação em curso de programação em 1985. Microsoft Certified Professional desde 2000, entre outros títulos oficiais de diversos grandes fabricantes internacionais de software, também criou cursos e provas oficiais voltados à programação de computadores. Tem experiência na área de Ciência da Computação, com ênfase em Engenharia de Software, atuando principalmente nos seguintes temas: análise e desenvolvimento de sistemas, engenharia de software, métodos de pesquisa e métodos ágeis.